
INSIGHT
Assurance is dead. Long live orchestrated assurance.
Legacy service assurance procedures are not living up to today’s requirements on customer experience and service quality. Thus, we need to rethink service assurance, abandon practices with a strict reactive focus on events and alarms, and instead start to think about what really matters. Simply renaming traps and syslog streams to “telemetry” will not help. Neither will dropping event and alarm information into a big Data lake.
Let us start by analyzing the underlying problems.
Disconnect between Service Fulfillment and Service Assurance

First of all the service fulfillment/delivery and service assurance processes are disconnected. The delivery team provisions a service without knowing if it really works. There is very little automatic hand-over to the operations team on how to monitor the service. In many cases, the assurance team has to start from scratch, perhaps not even realizing the service exists until a customer calls and complains. Furthermore, to “help” them understand the service they have incomplete service discovery tools and inventories.
Sub-optimal activation testing
Frequently, services are not tested at delivery, which, as mentioned above, is a considerable problem. In many cases, there is simply no activation testing carried out. Customers detect if the service is working as expected. In other cases, a simple ping is done at service delivery. But that has very little to do with the customer experience. Furthermore, legacy testing techniques, when at all performed, often require manual and expensive field efforts. This, of course, is too slow and inefficient.
Very often neither customer care nor the operations team has real insights into how the service actually is working.
A poor understanding of the end-user experience

Today, service assurance practices focus on resources, servers, applications and network devices. Accordingly, assurance data consists of log files and counters relating to these resources. This, however, has little to do with how services are working. You can have a fault on a device that is not affecting a customer and, furthermore, many customer issues have nothing to do with a fault. Most under-performing services are due to a less than optimal configuration, and alarm or performance systems will not detect these problems.
The industry has begun to realize that service assurance is not living up to requirements. But rather than identifying the root cause and doing something about it, it seems all too often we are looking for a free lunch instead – the Big data promise. You can’t just throw incomplete and low-level data into a Big data repository, and expect to draw conclusions about service health.
Fear the mapping-machine
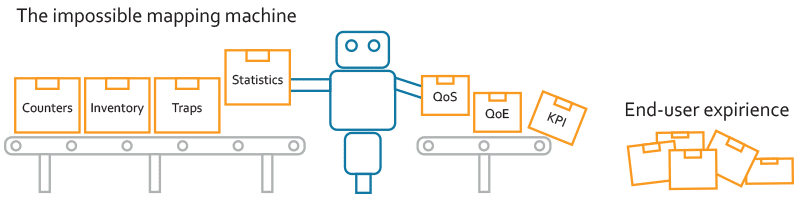
Unfortunately, Big data alone does not bring us closer to the goal. Calculating service health from low-level resource data is not obvious. The mapping function is simply not available in Big data frameworks, while with machine learning, the training sets for the service data are lacking.
Orchestrated Assurance
At Data Ductus, we work with technology partners to provide solutions which we believe bring us closer to a resolution.
The principles are the following:
- Measure service metrics directly. Do not try to infer them from resource data.
- Use automated tests in every service delivery.
- Tie the orchestrator and assurance systems together so that the orchestrator automatically performs the testing and enables monitoring.
We are always eager to learn from others and to share ideas. If you have comments or would like to assess potential joint initiatives, do not hesitate to get in touch.